Monte Carlo#
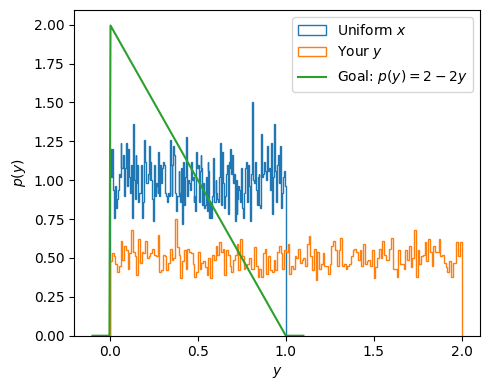
Here we describe how to represent probability distributions numerically with samples. For example, consider a single random variable \(X\) with PDF \(p_X(x)\). We can of course represent this by the function \(p_X(x)\), but this can be tricky, especially in higher dimensions.
An alternative is to use a large set of samples \(\vect{x} = \{x_0, x_1, \dots, x_{N-1}\}\). To get back to the PDF we use a histogram.
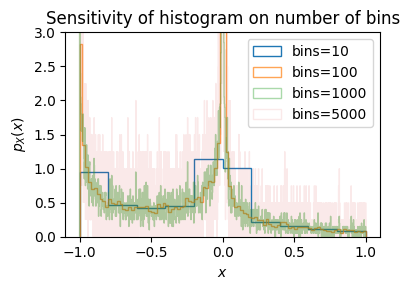
Do It! How do you sample a given PDF \(p(y)\) from a uniform sample?
Given a set \(\vect{x}\) uniformly sampled from the interval \(x\in [0, 1]\), how can you transform them \(y=f(x)\) to sample a desired PDF \(p(y)\)? Test your answer with the code below. Try to get samples with the following PDF:
\[\begin{gather*}
p(y) = \begin{cases}
2(1-y) & y \in [0, 1]\\
0 & \text{otherwise}
\end{cases}
\end{gather*}\]
# Random number generator - seed for reproducibility
rng = np.random.default_rng(seed=2)
Ns = 10000 # Number of samples
x = rng.random(size=(Ns)) # Uniform distribution
# Your answer goes here ####
y = 2*(1-x)
@np.vectorize
def p(y):
if y < 0 or y > 1:
return 0.0
return 2*(1-y)
fig, ax = plt.subplots(figsize=(5,4))
ax.hist(x, bins=200, density=True, histtype='step', label="Uniform $x$")
ax.hist(y, bins=200, density=True, histtype='step', label="Your $y$")
y_ = np.linspace(-0.1, 1.1, 200)
ax.plot(y_, p(y_), label="Goal: $p(y) = 2-2y$")
ax.legend()
ax.set(xlabel="$y$", ylabel="$p(y)$")
plt.tight_layout();