Random Variables#
Here we summarize some properties of random variables. Let \(X\), \(Y\), etc. be random variables with probability distribution functions (PDFs) \(P_X(x)\), \(P_Y(y)\) etc.
Example: Normal (Gaussian) Distributions
A normally distributed variable with mean \(\mu\) and variance \(\sigma\) has PDF:
A multivariate normal distribution of \(N\) variables with mean \(\vect{\mu}\) and covariance matrix \(\mat{C}\) has the following PDF:
Random variables can be combined using the [algebra of random variables]. The important results can be derived from the following important result.
Important
The probability distribution function (PDF) of a random variable \(Z = f(\vect{X}) = f(X_1, X_2, \dots, X_{N})\) that is a function of \(N\) random variables \(\vect{X}\) with PDF \(P_X(\vect{z})\) is:
Function of a Random Variable#
Let \(z=f(x)\) be some function. The variable \(Z=f(X)\) has PDF
where the sum is over all independent solutions to \(f(x) = z\).
def C_Z_inv(x):
"""Return z where x = C_Z(z)."""
z = 2/np.pi * np.arcsin(2*x-1) # Good initial guess
for _n in range(4): # 4 steps give machine precision
z -= ((np.polyval([-1, 0, 3, 2], z) - 4*x)
/ (np.polyval([-3, 0, 3], z) + 1e-32))
return z
rng = np.random.default_rng(seed=2)
X = rng.random(size=20000) # Uniform distribution of X from 0 to 1
Z = C_Z_inv(X)
x = np.linspace(0, 1)
z = np.linspace(-1, 1)
fig, ax = plt.subplots()
kw = dict(histtype='step', alpha=0.8, density=True)
plt.hist(X, bins=100, ec="C0", **kw)
plt.hist(Z, bins=100, ec="C1", **kw)
plt.plot(x, 0*x + 1, '--C0', label='X')
plt.plot(z, 3*(1-z**2)/4, '--C1', label='Z')
ax.legend();
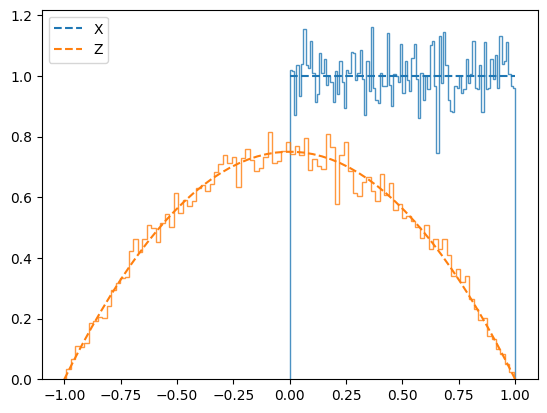
Sum of Independent Random Variables#
The distribution of the sum \(Z = X+Y\) of two independently distributed random variavles is thus the convolution \(P_{X+Y} = P_X * P_Y\) of the distributions:
Example: Sum of Independent Normal Distributions
The sum or normally distributed random variables over the same space is also normal with the following mean and covariance matrix
If the spaces are not the same, then the vectors and matrices must be organized appropriately so corresponding spaces overlap, with the other spaces add in separate dimensions.
Note: The distributions must be independent, or at least jointly normal, otherwise the resulting distribution might not be a multivariate normal distribution.
Product of Independent Random Variables#
The distribution of the product \(Z = XY\) of two independently distributed random variables is:
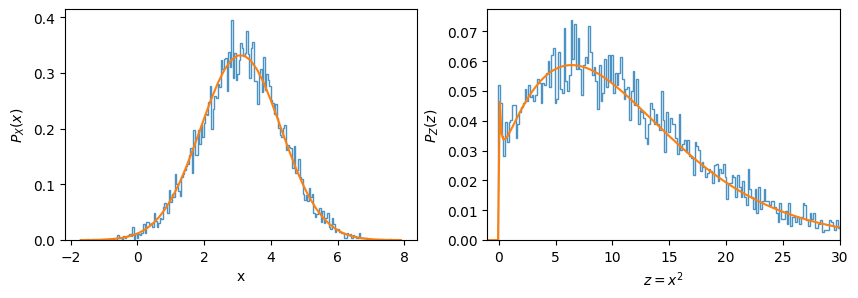
Example: Square of a Normal Variable
Let \(X\) be normally distributed, then \(Z = X^2\) has the following distribution:
If the mean is zero, then this simplifies:
If the spaces are not the same, then the vectors and matrices must be organized appropriately so corresponding spaces overlap, with the other spaces add in separate dimensions.
Note: The distributions must be independent, or at least jointly normal, otherwise the resulting distribution might not be a multivariate normal distribution.
Working with random variables is fraught with opportunities to make algebraic mistakes, forgetting factors of 2 etc. Checking with code is almost trivial, so do it! (The hardest part is choosing good parameters for the histograms.)
rng = np.random.default_rng(seed=2)
mu = 3.1
sigma = 1.2
N = 10000
X = rng.normal(loc=mu, scale=sigma, size=N)
Z = X**2
x = np.linspace(mu-4*sigma, mu+4*sigma)
z = np.linspace(-1, 30, 200)
def P_X(x):
return (np.exp(-(x-mu)**2/2/sigma**2)
/ np.sqrt(2*np.pi * sigma**2))
def P_Z(z):
x = np.sqrt(abs(z))
df_dx = 2*abs(x)
return np.where(z < 0, 0, (P_X(x) + P_X(-x))/df_dx)
kw = dict(histtype='step', alpha=0.8, density=True)
fig, axs = plt.subplots(1, 2, figsize=(10, 3))
ax = axs[0]
ax.hist(X, 200, **kw)
ax.plot(x, P_X(x))
ax.set(xlabel="x", ylabel="$P_X(x)$")
ax = axs[1]
ax.hist(Z, bins=z, **kw)
ax.plot(z, P_Z(z), '-', scaley=False)
ax.set(xlim=(-1, 30), xlabel="$z=x^2$", ylabel="$P_Z(z)$");
Chi-Squared Distribution#
As an extended example, consider the \(\chi^2\) distribution for a linear model with normally distributed errors \(e_n\), each with mean \(0\) and variance \(\sigma_n^2\). Then, we have:
Let \(\tilde{e}_n = e_n/\sigma_n\). We have the following PDFs:
The last step involves adding independent distributions, which is done with convolution
and gives the chi-square distribution as described in section 6.14.8 of
[Press et al., 2007]. This can be computed using scipy.stats.chi2. It has
mean \(\nu\) and variance \(2\nu\). From this, we can also compute the distribution for
\(\chi^2_r\):
The chi-squared distribution also arises when determining confidence regions of a multivariate normal distribution of \(\nu\) parameters \(\vect{a}\) with mean \(\bar{\vect{a}}\) and covariance matrix \(\mat{C}\):
from scipy.stats import chi2, norm
chi2_rs = np.linspace(-0.1, 4, 100)
fig, axs = plt.subplots(1, 2, figsize=(10, 3))
for nu in [1, 2, 3, 4, 20, 50, 100]:
chi2s = chi2_rs * nu
l0, = axs[0].plot(chi2s, chi2.pdf(chi2s, df=nu), label=rf"$\nu={nu}$")
l1, = axs[1].plot(chi2_rs, nu*chi2.pdf(nu*chi2_rs, df=nu), label=rf"$\nu={nu}$")
axs[0].plot(chi2s, np.exp(-(chi2s - nu)**2/4/nu)/np.sqrt(4*np.pi*nu),
':', c=l0.get_c())
sigma = np.sqrt(2/nu)
axs[1].plot(chi2_rs, np.exp(-(chi2_rs - 1)**2/2/sigma**2)/np.sqrt(2*np.pi*sigma**2),
':', c=l1.get_c())
mean_chi2, var_chi2 = chi2.stats(df=nu, moments='mv')
print(f"𝜈={nu}, χ² mean={mean_chi2}, var={var_chi2}")
axs[0].set(xlabel=r"$\chi^2$", ylabel=r"$P_{\chi^2, \nu}(\chi^2)$",
xlim=(-0.1, 20), ylim=(0, 0.6))
axs[1].set(xlabel=r"$\chi^2_r$", ylabel=r"$P_{\chi^2_r, \nu}(\chi^2_r)$")
for ax in axs:
ax.legend();
𝜈=1, χ² mean=1.0, var=2.0
𝜈=2, χ² mean=2.0, var=4.0
𝜈=3, χ² mean=3.0, var=6.0
𝜈=4, χ² mean=4.0, var=8.0
𝜈=20, χ² mean=20.0, var=40.0
𝜈=50, χ² mean=50.0, var=100.0
𝜈=100, χ² mean=100.0, var=200.0
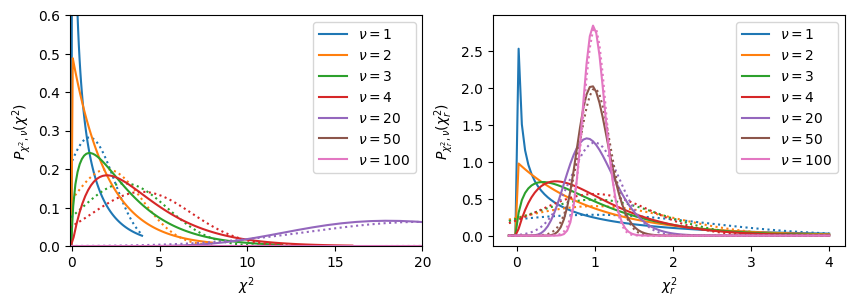
These results indicate why it is important to work out the confidence intervals carefully. If there are many degrees of freedom \(\nu > 20\), then \(\chi^2_r\) is tightly peaked with \(\sigma = \sqrt{2/\nu}\) about the mean value of \(1\) (dotted lines):
But, if you have limited data, then the distribution has some significant deviations and you should use the CDF of the actual \(\chi^2\) distribution to compute your confidence intervals.
Why \(\nu = N - M\)?#
When performing an actual maximum likelihood analysis, the distribution of \(\chi^2\) after minimizing is a [chi-square distribution] with \(\nu = N-M\) where there are \(N\) data points and \(M\) parameters in the model. This comes from the fact that we don’t compute \(f(x_n, \vect{a})\) with \(\vect{a}\) being the physical parameters as assumed in the model \(y_n = f(x_n, \vect{a}) + e_n\), but rather, we compute \(f(x_n, \bar{\vect{a}})\) where \(\bar{\vect{a}}(\vect{e}) \neq \vect{a}\) maximizes the likelihood for a given set of data, and therefore, depends on \(\vect{e}\). This additional dependence reduces \(\nu\) from \(N\) to \(\nu = N-M\).
Confidence Regions#
Another reason that the chi square distribution is useful is to find confidence regions. Give a set of \(\nu\) random variables distributed as \(P(\vect{a})\). The HDR confidence region with confidence level \(p\) is the region where \(P(\vect{a}) < P_{p}\) such that \(100p\%\) of the results like within this region (i.e. \(p=0.95\) corresponds to a \(95\%\) confidence level):
If \(P(\vect{a})\) is a multivariate normal distribution with zero norm, then we can transform to \(\chi^2\) which is distributed as above, solving the problem:
Hence, \(p(\chi^2_p)\) is just the CDF of the chi square distribution with \(\nu\) degrees of
freedom, and the appropriate value of \(\chi^2_p\) is the inverse of this, which can be
computed using the scipy.stats.rv_continuous.ppf() method of the
scipy.stats.chi2 distribution:
from scipy.stats import chi2, norm
sigmas = [1, 2, 3, 4]
ps = norm.cdf(np.sqrt(sigmas)) - norm.cdf(-np.sqrt(sigmas))
print("Confidence levels:")
print(", ".join([f"{100*_p:.2f}% ({_n}σ)" for _n, _p in zip(sigmas, ps)]))
for nu in [1, 2, 3, 4]:
print(f"χ²ₚ (𝜈={nu}): {chi2.ppf(ps, df=nu).round(2)}")
Confidence levels:
68.27% (1σ), 84.27% (2σ), 91.67% (3σ), 95.45% (4σ)
χ²ₚ (𝜈=1): [1. 2. 3. 4.]
χ²ₚ (𝜈=2): [2.3 3.7 4.97 6.18]
χ²ₚ (𝜈=3): [3.53 5.21 6.67 8.02]
χ²ₚ (𝜈=4): [4.72 6.62 8.24 9.72]
Note that for \(\nu = 1\) degree of freedom, the \(n\sigma\) confidence regions correspond to \(\chi^2_p = n\), but for higher dimensions, this is not the case.
To see that the distribution is equivalent to the chi squared distribution, note that
where we first transform to a new set of variables \(\vect{x}\) such that \(\vect{a} = \mat{L}\vect{x}\) where \(\mat{C} = \mat{L}\mat{L}^T\). Here each components of \(\vect{x}\) is independently distributed with a zero-mean, \(\sigma=1\) normal distribution. We then transform to \(\chi^2\) which is the sum of \(\nu\) squares of such distributions, giving \(P_{\chi^2, \nu}(\chi^2)\) as computed above.
The normalization factor changes with a determinant of the Jacobian \(\det\mat{L} = \sqrt{\det\mat{C}}\) so we have: